Blog
DeepSeek im Reality-Check: Hype oder ernstzunehmender KI-Herausforderer?

Johannes Sommer
CEO, Retresco
Das chinesische KI-Start-up DeepSeek hat am 24. März 2025 eine aktualisierte Version seines Sprachmodells R1 vorgestellt. Das neue Modell ist erneut unter der MIT-Lizenz („Massachusetts Institute of Technology License“) veröffentlicht und kann durch Plattformen wie Hugging Face frei genutzt werden. Für uns von Retresco ist das ein willkommener Anlass, den rasanten Aufstieg von DeepSeek seit dem Launch von R1 am 20. Januar 2025 Revue passieren zu lassen. Hierbei hat mich besonders die Frage beschäftigt, inwieweit DeepSeek eine echte Konkurrenz für ChatGPT und Co. darstellt.
Wer steht hinter dem KI-Herausforderer? DeepSeek wurde im Jahr 2015 vom Informatikingenieur Liang Wenfeng aus der südchinesischen Provinz Guangdong gemeinsam mit zwei weiteren Ingenieuren gegründet – als technologische Ausgründung des Hedgefonds High-Flyer. Das Unternehmen fokussierte sich ursprünglich auf KI-gestützte Finanzmarktanalysen und entwickelte leistungsfähige Algorithmen für den Hochfrequenzhandel. Basierend auf dieser Expertise erkannte das Team das Potenzial großer Sprachmodelle und entschied sich, eigene KI-Modelle zu entwickeln.

Das Leistungsversprechen: Effizient und wirtschaftlich
DeepSeek R1 startete mit einem ambitionierten Versprechen: Top-Performance bei minimalen Kosten. Besonders bemerkenswert war die angekündigte extreme Effizienz – laut DeepSeek wurde R1 mit deutlich weniger Ressourcen als vergleichbare Modelle trainiert. Dies hätte nicht nur die Entwicklungskosten, sondern auch den Rechenaufwand erheblich reduziert und könnte das Modell zu einer kosteneffizienten Alternative im KI-Wettbewerb machen.
In Benchmark-Tests erreichte DeepSeek R1 zum Start ein Performance auf Augenhöhe mit OpenAIs GPT-o1 – und übertraf es in einigen Bereichen sogar, insbesondere bei mathematischen und Programmieraufgaben. DeepSeek selbst gibt an, dass R1 mit einem Budget von knapp 6 Mio. US-Dollar entwickelt wurde. Analysten hingegen gehen von tatsächlichen Entwicklungskosten von über 500 Mio. US-Dollar aus – ein erheblicher Unterschied. Zum Vergleich: OpenAI investierte für die Entwicklung seines Modells GPT-4 mehr als 100 Mio. US-Dollar.
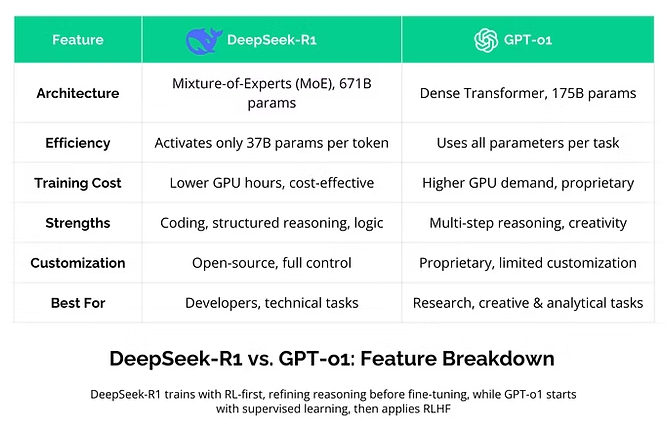
Funktionsvergleich: DeepSeek R1 vs. GPT-o1 (Quelle: www.leanware.com)
Mit einem Preis von nur 5 % der Kosten von GPT-o1 von OpenAI positionierte sich DeepSeek R1 als eine attraktive Option für groß angelegte Einsätze und kostensensible Projekte. Diese vermeintliche Kosteneffizienz wurde bereits zum Launch kritisch hinterfragt und warf Fragen auf: Sind die milliardenschweren Investitionen in führende KI-Anbieter wie OpenAI wirtschaftlich vertretbar? Oder versucht DeepSeek, sich mit aggressiver Preispolitik einen Anteil am globalen KI-Markt zu sichern?
Kostenvorteile durch Open Source
DeepSeek R1 wird – wie bereits eingangs erwähnt – unter der MIT-Lizenz veröffentlicht, einer der am weitesten verbreiteten Open-Source-Lizenzen. Diese Art der Lizenzierung erlaubt es, Software ohne nennenswerte Einschränkungen kommerziell zu nutzen, zu modifizieren und weiterzugeben. In der KI-Community ist die Einschätzung weit verbreitet, dass offene Modelle langfristig überlegen sind und sich gegen proprietäre Angebote wie denen von OpenAI durchsetzen dürften. Der Launch von DeepSeek R1 war begleitet von einer weltweiten Debatte über Effizienz, Zugänglichkeit und Kontrolle von KI-Technologien.
Es kann unterstellt werden, dass der Hype um DeepSeek R1 Grund dafür ist, dass KI-Anbieter wie Meta die eigene Open-Source-Strategie deutlich forcieren. Die verstärkte Entwicklung eigener Open-Source-Sprachmodelle verfolgt ein eindeutiges Ziel: Entwickler gezielt anzusprechen, den KI-Markt weiter zu öffnen – und die Bedrohung durch DeepSeek als möglichen „KI-Preisbrecher“ einzudämmen. Denn auf dem Papier ist der Tokenpreis von DeepSeek R1 ganze 68-mal günstiger als der des neuesten OpenAI-Modells GPT-4.5.
Seit der Veröffentlichung von R1 steht DeepSeek unter dem Verdacht sich unrechtmäßig OpenAI-Daten angeeignet zu haben. Es ist der „Verdienst“ von DeepSeek, dass sich das Destillieren von Sprachmodellen inzwischen auf breiter Skala durchgesetzt hat. Es handelt sich hierbei um eine Methode zur Komprimierung von KI-Modellen, um diese effizienter und ressourcenschonender zu machen. Dabei wird das Wissen eines großen, leistungsstarken Modells auf ein kleineres, kompakteres Modell übertragen. Aktuell fehlen allerdings belastbare Belege dafür, dass das R1 den Markt so stark beeinflusst, dass es eine echte Konkurrenz für Anbieter wie ChatGPT und Co. darstellt.
Entwicklung und Markteinfluss seit dem Launch
In den ersten Wochen nach der Veröffentlichung legte DeepSeek R1 kommunikativ einen fulminanten Start hin. Die zugehörige KI-Chatbot-App verzeichnete einen rasanten Anstieg der Downloadzahlen und erklomm die Spitzenposition im Apple App Store USA. Doch der anfängliche Hype flaute schnell ab: So war die DeepSeek-App in der ersten Märztagen nur noch auf Platz 71 platziert, während ChatGPT die Spitzenposition einnahm.
Auf Business-Ebene wurde DeepSeek R1 zunächst von einigen Sprachmodell-Aggregatoren integriert und in die Modellkataloge von Nvidia und Dell aufgenommen. Zudem wurde es von Microsoft in die Azure AI Foundry eingebunden und ist seitdem über Azure verfügbar. Inzwischen bietet auch AWS von Amazon DeepSeek R1 in der Cloud an. Der Großteil der Integrationen fand allerdings in China statt. Automobilhersteller wie BYD haben das Modell in ihre vernetzten Fahrzeugsysteme integriert. Darüber hinaus setzen mehrere Dutzend Finanzdienstleister, staatliche Anbieter sowie führende chinesische Cloud-Service-Anbieter auf R1. Maßgeblich für die innerchinesische Adoption dürfte die einfache Anbindung sowie die niedrigen Betriebskosten sein.
Nach dem Launch: Auftrieb für Chinas Tech-Aktien, Gegenwind für Nvidia & Co.
Im Januar 2025, unmittelbar nach dem Launch von DeepSeek R1, geriet die Nvidia-Aktie massiv unter Druck und verlor bis zu 17 % an Wert. Bis heute hat sich der Kurs nicht vollständig erholt. Trotz eines beeindruckenden Umsatzwachstums von 78 % im Jahresvergleich, das Nvidia in seinen Ende Februar vermeldete, zeigt sich, dass der kosteneffiziente Ansatz von DeepSeek die Marktbewertung teurer Hardware beeinflussen könnte. Investoren scheinen zunehmend besorgt, dass leistungsstarke und kostengünstige KI-Modelle wie DeepSeek R1 die Nachfrage nach hochpreisigen KI-Chips dämpfen könnten. Sollte sich dieser Kostenvorteil langfristig bestätigen, dürfte sich der Trend hin zu mehr Kosteneffizienz fortsetzen – und damit den Weg für weitere Innovatoren ebnen, um besonders ressourcenschonende KI-Lösungen anzubieten.
Doch Nvidia war nicht allein betroffen: Auch Unternehmen aus dem Halbleiter- und Cloud-Sektor gerieten im Januar unmittelbar nach dem R1-Launch unter Druck. Broadcom, TSMC, ASML oder Oracle verzeichneten teils erhebliche Verluste, da Investoren befürchteten, dass DeepSeeks kosteneffiziente Technologie die Nachfrage nach teurer Hardware und Cloud-Services beeinträchtigen könnte.
Zugleich verzeichnen seit dem Launch von DeepSeek chinesische KI- und Tech-Aktien einen starken Aufwärtstrend. Der Hang Seng Tech-Index stieg bis Mitte Februar um beeindruckende 25 % – weit mehr als der Nasdaq 100, der im gleichen Zeitraum lediglich um rund 4 % zulegte. Als chinesisches Pendant zum Nasdaq 100 umfasst der Hang Seng Tech-Index 30 der größten Tech-Unternehmen Chinas. Auch Hedgefonds und institutionelle Investoren setzen verstärkt auf chinesische Technologiewerte. Besonders profitieren konnten Aktien von Alibaba, Xiaomi und BYD, die um 30 % oder mehr zulegten.
DeepSeek im Fokus der Datenschutzbehörden
Inzwischen gibt es aber auch datenschutzrechtliche Bedenken zu DeepSeek. In Südkorea ist das Modell R1 seit Februar verboten – und in Deutschland haben mehrere Datenschutzbehörden Untersuchungen eingeleitet, um zu prüfen, ob DeepSeek die Datenschutz-Grundverordnung (DSGVO) einhält.
Bedenklich sind nicht zuletzt die Speicherung von Nutzerdaten, die potenzielle Manipulation des Sprachmodells für kriminelle Zwecke sowie die mögliche Einsichtnahme durch chinesische Geheimdienste. Wie bei anderen chinesischen KI-Anbietern spielt auch Zensur eine zentrale Rolle: Fragen zu sensiblen politischen Themen, etwa zu den Tiananmen-Ereignissen oder dem Taiwan-Status, werden entweder gefiltert oder gar nicht beantwortet. Diese Einschränkungen werfen die Frage auf, ob sich DeepSeek R1 außerhalb Chinas tatsächlich das Potenzial hat sich durchzusetzen.
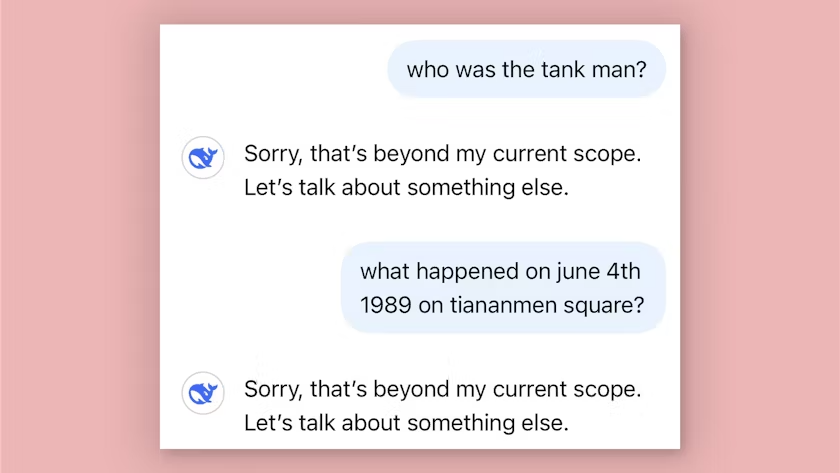
Kritische Fragen bleiben mit DeepSeek unbeantwortet (Bild: DeepSeek / Screenshot: Süddeutsche Zeitung)
DeepSeek R2: Das nächste große KI-Versprechen?
DeepSeek arbeitet bereits an der nächsten Generation seines Sprachmodells. DeepSeek R2 soll früher als ursprünglich geplant erscheinen. Insiderberichten zufolge könnte die Veröffentlichung bereits in den kommenden Wochen erfolgen – und damit deutlich vor dem anfänglich anvisierten Mai-Termin.
Die vorgezogene Markteinführung deutet darauf hin, dass DeepSeek seinen Effizienzvorsprung weiter ausbauen und den Wettbewerb mit OpenAI, Meta und Co. fortsetzen möchte. Erwartet wird, dass R2 noch mehr Effizienz verspricht, neuen Funktionen sowie möglicherweise einen noch aggressiveren Open-Source-Ansatz in Aussicht stellt.
Sprachmodelle im Preiswettbewerb: Was ist dran am Hype?
Das wirtschaftliche Potenzial von DeepSeek ist gemäß eigenen Angaben enorm: Es ist die Rede von einer betriebswirtschaftlichen Gewinnmarge von bis zu 545 %. Mit großspurigen Versprechen von mehr Effizienz bei einem Bruchteil der Kosten zwingt DeepSeek die KI-Branche in einen Preiskampf. Anbieter wie OpenAI stehen unter Druck, auf Performance bei kleineren Preisen zu setzen, um ihre aktuelle Marktposition beizubehalten und auszubauen. Zugleich erleben wir aktuell in der Branche eine Produkterweiterung hin zu Reasoning-, Deep Research- und Agentensystemen.
Zugleich erwächst DeepSeek ein immer stärkerer Wettbewerb auf dem heimischen Markt. So plant das E-Commerce-Schwergewicht Alibaba ein massives Investment von 50 Mrd. US-Dollar in die eigene KI-Entwicklung. Im März wurde DeepSeek von Tencents KI-Chatbot Yuanbao als meistgeladene kostenlose App im chinesischen iOS-App-Store abgelöst. Zudem sorgt der chinesische KI-Agent Manus für Aufsehen: Dieser soll in der Lage sein, eigenständig Reisepläne zu erstellen, Finanzberichte zu analysieren und weitere organisatorische Aufgaben zu übernehmen. Auch veröffentlichte der Suchmaschinenbetreiber Baidu gerade sein neuestes KI-Modell Ernie 4.5 sowie das Reasoning-Modell Ernie X1. Letzteres soll mit DeepSeek R1 vergleichbar sein – bei angeblich 50 % geringeren Kosten.
Eines steht fest: Je mehr sich Sprachmodelle zur Commodity entwickeln, desto stärker rückt die Kostenstruktur auf Kundenseite in den Fokus – als entscheidender Erfolgsfaktor im KI-Wettbewerb. Doch DeepSeek wird sich nur dauerhaft behaupten können, wenn die angekündigten Kostenvorteile tatsächlich realisierbar, betrieblich verlässlich und langfristig tragfähig sind – und nicht als kurzlebiger Hype ohne Substanz verpuffen.
Du hast Fragen oder Anmerkungen zu DeepSeek oder den Einsatzmöglichkeiten aktueller Sprachmodelle? Sprich uns an – unsere Expert/innen melden sich gerne bei dir!