
Intelligent Q&A Systems – Ready to Use, Easily Customisable
Are you looking for an interactive, dialogue-based question-answering system — like ChatGPT — but precise and based on your own content? Would you like to leverage existing data and content pools efficiently while seamlessly integrating external sources?
No problem! Our question-answering systems are ready to use right away and can be seamlessly connected to your data via standard API. Expand the range of questions that can be answered to topics for which no specific editorial content is available by relying on agent-based data integration. The result is highly accurate, context-sensitive answers in natural language.
This allows you to increase user engagement at all desired touchpoints and significantly strengthen loyalty to your content and offerings. You can also benefit from comprehensive quantitative and qualitative analyses directly from the Q&A system: performance KPIs, transparent usage patterns and valuable thematic insights from real user questions.
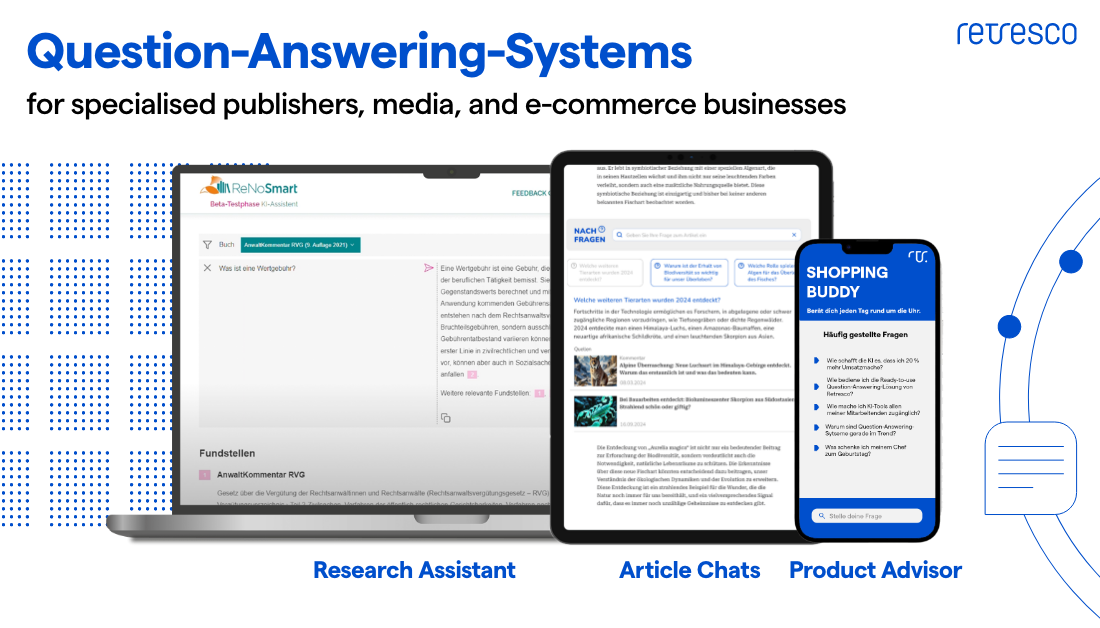

Added Value for Media Companies, Publishers & Beyond
With our Q&A solution, you and your teams benefit in multiple ways:
Ideal for Media, Publishers & Content Providers

Benefits for End Users & Employees
Your customers and teams will benefit in multiple ways:









What Makes Our Question-Answering Systems Unique?
|
Retresco’s Q&A Solution
|
Similar Systems
|
||
|---|---|---|---|
| Data Integration | Agent-based retrieval-augmented generation (RAG) with dynamic API integration of external and internal data sources (CMS, archives, databases, live feeds). Enables in-depth, up-to-date and customer-specific responses specifically for media companies (stock market, weather, traffic, etc.). | Classic RAG or static data connections with limited API integration; often restricted to predefined data sources or document sets. | |
| Front-end widget | Quickly ready to go with a CI-compliant widget (branding, colours, labels, disclaimer). Embed directly into articles, sections, dossiers or apps – without complex front-end projects. | Often individual front-end development or isolated chat interfaces without native integration into the relevant content environment. | |
| Content quality | Prioritises curated, journalistically verified data sources with precise source citations and traceable references. Minimises misinformation and distorted content. | Higher risk of inaccurate or distorted content due to uncurated databases, zero-shot generation or missing source references. | |
| Semantics | Advanced semantic analyses and media ontologies for precise contextual understanding, topic assignment and content relevance in editorial environments. | Often keyword- or embedding-based search without domain-specific semantics; lower context hit rate. | |
| Adaptability | Individually configurable for publishers and media companies (departments, taxonomies, content types, workflows, paywall logic). | Generic Q&A setups with limited adaptation to media workflows or editorial structures. | |
| Media expertise | Optimised for journalistic research, content generation, reader services, archive information and knowledge portals in media organisations. | Broad knowledge approach without specific media or publishing focus and without optimised output formats. | |
| Multilingualism | Multilingual output with localised terminology, SEO optimisation and linguistic fine-tuning for different target markets and regions. | Focus on English; localisation mostly via simple translation without SEO or style adaptation. | |
| Scalability | Designed for large content repositories, historical archives and continuous data streams (e.g. news feeds). | Limitations with larger or heterogeneous data sets and real-time updates. | |
| Automation | Automated generation, prioritisation, and updating of responses based on trends, usage signals, and editorial rules. | Mostly just reactive response generation without strategic weighting or prioritisation. | |
| Editorial control | Clear interface with detailed insights into retrieval, source and generation processes for editorial control. | Technically oriented interfaces with low transparency for specialist users. | |
| Conversational Analytics | Detailed evaluations and clusters on usage, question patterns, and topics of interest—can be integrated directly in the front end or automatically via API push into analytics and content management systems and dashboards. | Barely structured evaluation of user questions. Mostly just simple chat logs without systematic analysis or integration into analytics/editorial systems. | |
| Chat history | Easily structured, nameable and retrievable chat histories for editorial teams, knowledge management and research documentation. | Chats are often fleeting or cannot be organised systematically; limited reuse. | |
| User feedback | User reviews, comments and correction notes for optimisation and quality assurance are provided via a module. | Rarely integrated feedback mechanisms; quality improvement mostly manual or external. | |
| Language model connection | Vendor-independent integration of current and specialised language models – updatable at any time. | Often tied to a specific language model or ecosystem. | |
| Updates | Regular development with new features specifically for media and publishing applications. | Standard updates without industry focus or customer-specific enhancements. | |
| Support | Consulting and implementation by AI and media experts with industry knowledge. | Generic support without specific media or SEO expertise. | |
